Online references to MongoDB’s aggregation pipeline:
- Aggregation Overview
- Quick Reference
- SQL to Aggregation Mapping
- Aggregation Pipeline Stages
- Aggregation Pipeline Operators
The ETL designer in Ambience 2020 onwards utilises MongoDB’s aggregation operators and pipelines in its steps and processes to return fast computed results. Click here to refer to data sample used in the example.
-
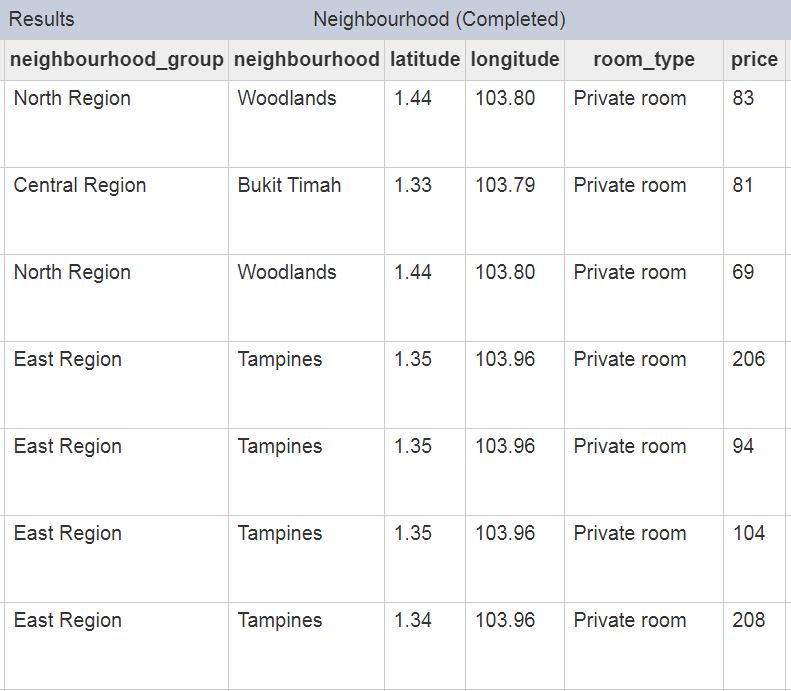
For example, below is a sample of room listing details in their respective neighbourhoods:
-
To create a summary based on the number of listings per neighbourhood group and average rental for private rooms, the following aggregation pipeline is constructed in a MongoDB data viewer, do note that quotes are required for queries written in Ambience and MongoDB data viewers as the aggregation pipeline is in JSON format:
db.getCollection('airbnb').aggregate( [ { "$match" : { "room_type" : "Private room" } }, { "$group" : { "_id" : "$neighbourhood_group", "count" : { "$sum" : 1 }, "avgPrice" : { "$avg" : "$price" } } }, { "$project" : { "Sector" : "$_id", "Total Listings" : "$count", "Average Rental" : "$avgPrice" } }, { "$sort" : { "Sector" : 1 } } ] ) -
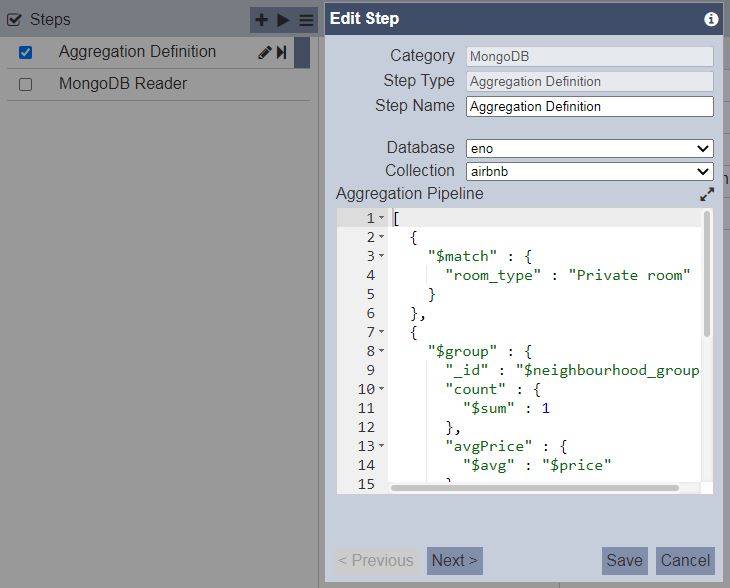
The same pipeline is applied as an Aggregation Definition step in the ETL designer without the collection and function as these are already defined at the ETL Designer UI level:
[ { "$match" : { "room_type" : "Private room" } }, { "$group" : { "_id" : "$neighbourhood_group", "count" : { "$sum" : 1 }, "avgPrice" : { "$avg" : "$price" } } }, { "$project" : { "Sector" : "$_id", "Total Listings" : "$count", "Average Rental" : "$avgPrice" } }, { "$sort" : { "Sector" : 1 } } ]Here’s a breakdown of the stages:
Filtering data by room type:
“$match” : {
“room_type” : “Private room”
}
Group and count by neighbourhood type:
“$group” : {
“_id” : “$neighbourhood_group”,
“count” : {
“$sum” : 1
}
Get the average rental rate:
“avgPrice” : {
“$avg” : “$price”
}Infer the schema of the data set; Sector, Total Listings, Average Rental:
“$project” : {
“Sector” : “$_id”,
“Total Listings” : “$count”,
“Average Rental” : “$avgPrice”
}
Sort the Sector column in ascending order:
“$sort” : {
“Sector” : 1
} -
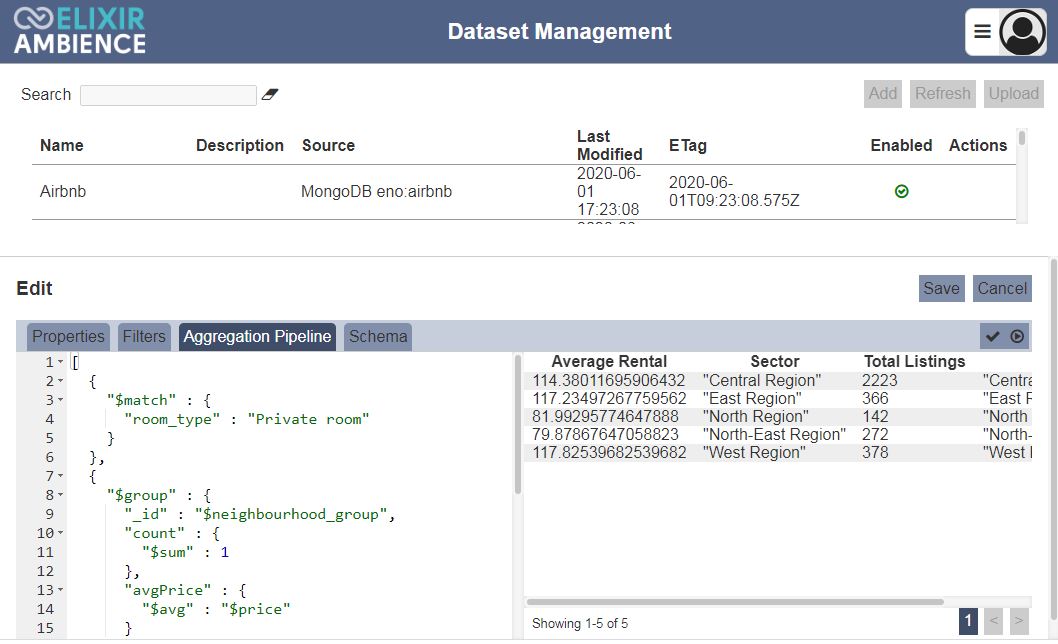
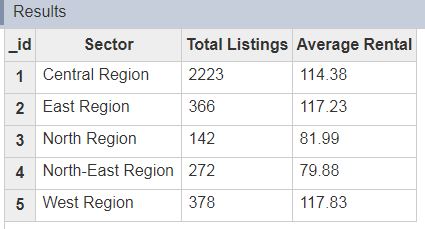
MongoDB returns a summarized data set with the number of listings per sector and average rental rate when running the Aggregation Definition in the ETL Designer:
-
Users are also able to apply aggregation pipelines to Ambience Datasets